Monitoring vs Logging vs Tracing 차이
- 마이크로서비스가 확장될수록 장애를 “빨리 발견하고(탐지)”, “정확히 파악하고(진단)”, “금방 고치는(복구)” 능력이 중요해집니다.
- 이때 필요한 세 가지가 바로
Monitoring,Logging,Tracing입니다.
📘 요약 Logging: 무슨 일이 일어났는지Tracing: 어디서 병목이 생겼는지Monitoring: 전체 상태가 어떤지
0. OpenTelemetry의 Observalbility
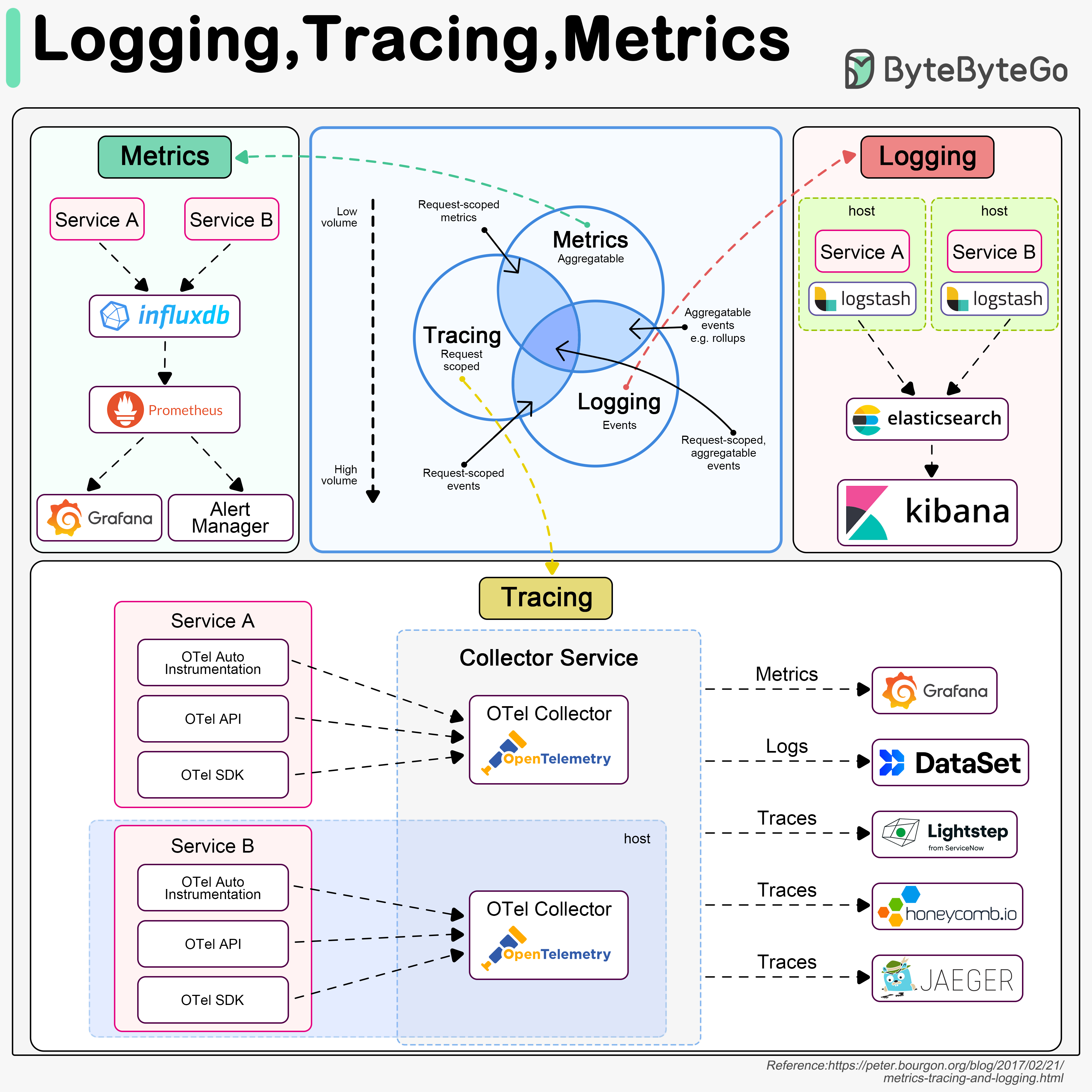
1️⃣ OpenTelemetry(OTel) 로 통합하여 관측(Observability) 구성한 이미지
2️⃣ Metrics (Monitoring)
- 시스템 상태를 숫자로 나타냄 (CPU, 요청 수, 지연 시간 등)
- Service A / B → Prometheus or InfluxDB → Grafana / AlertManager
- Low volume (데이터 양 적음)
- 집계 가능 (Aggregatable)
- “지금 상태가 어떤가?”를 보는 데 적합
3️⃣ Logging
- 서비스 내에서 발생한 이벤트 로그를 기록 (에러, 상태 변화, 접근 기록 등)
- Service A / B → Logstash → Elasticsearch → Kibana
- High volume (데이터 양 많음)
- “무슨 일이, 언제, 왜 일어났는가?” 분석에 유용
- 사람이 읽거나 시스템이 검색 가능하도록 구조화(JSON)
4️⃣ Tracing
- 하나의 요청이 여러 서비스를 거칠 때, 전체 흐름(Trace) 과 각 단계(Span) 의 지연 시간을 추적
- Service A / B → OpenTelemetry Collector → Jaeger / Honeycomb / Lightstep / Grafana
- Request-scoped (요청 단위)
- 지연 병목 분석용
- 서비스 간 호출 관계를 시각적으로 표시
🔸 서비스 내부
- 각 서비스는
OpenTelemetry(OTel)를 통해 데이터 생성 - OTel Auto Instrumentation: 자동 계측 (라이브러리로 함수 호출 추적)
- OTel API: 커스텀 스팬 추가 가능
- OTel SDK: 언어별 SDK (Java, Python, Go 등)
→ 이렇게 생성된Trace/Span데이터는 각 호스트의 OTelCollector로 전달
🔸 Collector
- Collector는 각 서비스에서 들어온 Telemetry 데이터를 모아서
가공/전달 - OTel Collector 는 로그, 메트릭, 트레이스 모두 지원
- Collector → 외부 백엔드(저장/시각화 툴)로 전송
5️⃣ 교차 영역
- 현실적으로는 세 데이터 유형이 서로 연결
Tracing+Metrics: 요청 단위의 메트릭 (예: 특정 요청의 응답 지연 시간)Logging+Tracing: 요청에 대한 상세 이벤트 기록 (에러 로그와 Trace 연동)Logging+Metrics: 이벤트를 수치화 가능 (에러 발생률, 로그 카운트 등)- ⭐️
세 개 모두 교차: “요청 단위의 이벤트를 수치로 분석” — 완전한Observability
6️⃣ 결론
OpenTelemetry는 이를 하나의 표준 파이프라인으로 통합해 개발·운영 환경에서 일관성 있는Observability구축을 가능하게 해주는Tool- 로그, 메트릭, 트레이스는 원래 별도의 도구로도 수집 가능
구분 설명 대표 도구 로그(Log) 시스템/애플리케이션 이벤트 기록 Fluentd,Fluent Bit,Logstash,Filebeat,Vector메트릭(Metric) CPU, 메모리, 요청 수 등 수치형 지표 Prometheus,InfluxDB,Telegraf,StatsD트레이스(Trace) 요청이 여러 서비스로 흘러가는 경로 추적 Jaeger,Zipkin,AWS X-Ray,Datadog APM
1. Logging
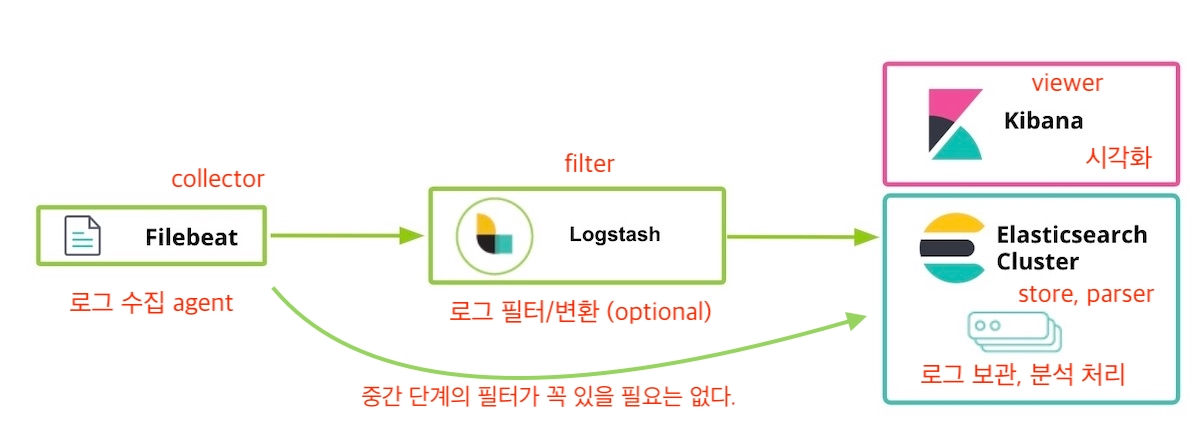
1️⃣ 로깅(Logging)의 목적
- 오류 및 시스템 상태 변화를 중앙 집중식으로 추적하고, 장애 발생 시 원인 진단(Investigate)과 분석(Diagnostics)을 가능하게 하는 것
- 문제 발생 시 “무슨 일이, 언제, 왜 일어났는지”를 알 수 있게 해주는 핵심 도구
- 단순한 기록이 아니라, 의미 있는 실행 가능한 정보(Actionable Data) 를 남기는 것이 중요
2️⃣ 로그 데이터의 종류
| 구분 | 설명 | 예시 |
|---|---|---|
| 사람이 읽는 로그 | 운영자가 즉시 확인 가능 | access_log, error_log |
| 구조화된 로그 | 기계 파싱·검색용 (JSON 등) | {"timestamp":"...","service":"auth","level":"ERROR","msg":"Invalid token"} |
3️⃣ 좋은 로그의 조건
- 간결하면서도 핵심 정보 포함
- 노이즈 최소화 — 불필요한 데이터(중복·무의미 메시지)는 제거
- 유용성 중심 설계 — 로그로 문제를 예방하거나 원인 추적이 가능해야 함
4️⃣ 로그 설계 시 고려사항
| 항목 | 설명 |
|---|---|
| 누가 로그를 보는가 | 주로 시스템 관리자, DevOps, 운영팀 |
| 목적 | 분석, 모니터링, 문제 예방 및 추적 |
| 보존정책 | 보안/법적 요구 및 데이터 중요도에 따라 구분 |
| 성능 영향 | 지나친 로그 출력은 CPU·I/O·네트워크 부하 유발 |
5️⃣ 엔터프라이즈 환경에서의 로그 계층화
| Tier | 설명 | 성능/비용 |
|---|---|---|
| Hot Tier | 실시간 분석용, 최근 로그 저장 | 빠름 / 비용 높음 |
| Warm Tier | 최근 수개월치 데이터, 조회 빈도 낮음 | 보통 |
| Cold Tier | 오래된 데이터, 장기보관용 | 저성능 / 저비용 |
| Frozen Tier | 거의 조회하지 않는 데이터, 스냅샷 보관 | 매우 저비용 |
| Coordinating Tier | Kibana 등에서 조회 요청 처리 전용 노드 | 부하 분산용 |
| ML Tier | 머신러닝 기반 이상 탐지, 패턴 분석용 | 선택적 |
→ 트래픽이 적은 서비스라면 Hot Tier 단일 구조도 충분하지만, 대규모 시스템에서는 계층화로 비용과 성능을 모두 확보할 수 있음
6️⃣ 실무 팁
- 필요한 로그만 남기기
- 중앙 집중 관리 → 여러 서버의 로그를 하나로 모아야 분석 가능
- 민감정보 마스킹 → 개인정보, 토큰 등은 반드시 익명화
- 보존주기 정의 → 3개월/6개월 단위로 티어 이동 또는 삭제
- 후처리 자동화 → 로그 기반 메트릭·알림·트레이싱 연계
2. Tracing
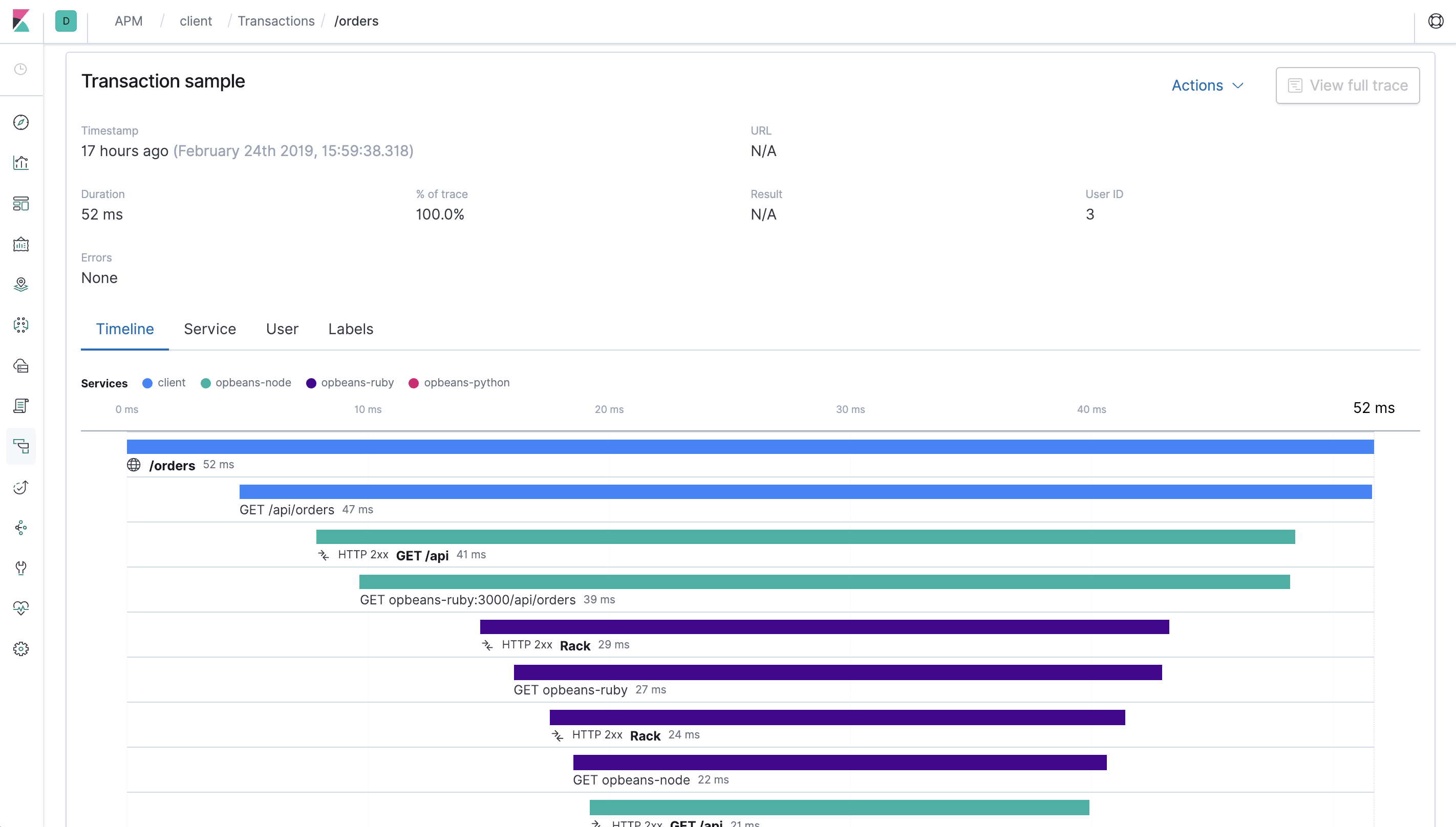
- 하나의 Trace = 요청 전체 흐름 (여기서는
/orders) - 하나의 Span = 요청 안에서 특정 작업 단위 (DB 호출, 내부 API, 외부 서비스 호출 등)
1️⃣ Tracing의 개념과 목적
Tracing은 애플리케이션 내부에서 요청이 어떻게 흐르고, 어느 지점에서 지연 또는 오류가 발생했는지를 추적하는 과정Logging이 개별 이벤트를 기록한다면,Tracing은 요청 전체의 흐름을 시각적으로 연결해 보여줌- 주로 사용자 요청의 시작부터 종료까지의 경로(End-to-End Path) 를 추적
- 성능 병목(Bottleneck) 파악, 서비스 간 연동 분석, 장애 원인 추적
2️⃣ Tracing이 제공하는 정보
Tracing은 단일 요청의Trace를 여러Span으로 나누어 기록합니다.
항목 설명 함수/서비스 이름 어떤 함수나 서비스가 호출되었는지 실행 시간(Duration) 각 단계가 얼마나 걸렸는지 전달된 파라미터 어떤 데이터가 오갔는지 호출 경로(Call Stack) 요청이 어떤 순서로 어떤 모듈을 거쳤는지 - 예시
사용자 요청 → API Gateway → Auth Service → DB Query
→ 외부 API 호출 → 응답 반환
→ 각 단계의 지연 시간 및 오류 위치 파악 가능
3️⃣ Tracing의 역할과 효과
| 역할 | 설명 |
|---|---|
| 문제 경로 추적 (Investigate) | 특정 요청이 실패하거나 느린 원인 파악 |
| 성능 최적화 | 병목 구간(예: DB, 외부 API, I/O 등) 식별 |
| 서비스 간 관계 시각화 | 마이크로서비스 간 호출 의존성 구조 파악 |
| 장애 복구 시간 단축 | 문제의 정확한 지점을 빠르게 확인 가능 |
→ 문제가 어디서 발생했는지를 찾아주는 도구 (로그보다 상위 개념)
4️⃣ Tracing 도입 시 고려사항
| 항목 | 설명 |
|---|---|
| 복잡한 레이어 구조 | 다단계 호출, 비동기(Event Driven) 시스템은 추적이 어려움 |
| 도입 방식 | 각 언어나 프레임워크별로 SDK 또는 자동 계측(Auto-Instrumentation) 필요 |
| 샘플링 전략 | 모든 요청을 추적하면 비용 증가 → 일부 요청만 기록(Head/Tail Sampling) |
| 수집 부하 관리 | Tracing 부하는 크지 않지만, 고트래픽 환경에서는 Collector 구성 중요 |
5️⃣ 실무 팁
- 웹 서비스라면 함수 단위보다는 외부 연동 구간(DB, HTTP, File I/O) 중심으로 추적
Tracing만으로 모든 문제를 해결하기보다,Metrics(모니터링) →Logging(상황 파악) →Tracing(원인 추적) 의 순서로 활용
3. Monitoring
1️⃣ Monitoring의 개념
Monitoring은 시스템의 동작 상태를 수치화(Metric) 하여 실시간으로 수집·분석·경고(Alert) 하는 과정Metric: 관측 가능한 수치 데이터 (CPU 사용률, 요청 수, 지연 시간 등)Monitoring: 이 Metric들을 지속적으로 측정·집계·분석하여 시스템의 이상 징후나 병목을 조기에 탐지
2️⃣ Monitoring의 목적
| 목적 | 설명 |
|---|---|
| 시스템 안정성 확보 | 서버, 네트워크, 애플리케이션의 상태를 실시간 추적 |
| 문제 조기 감지 | 장애, 자원 부족, 성능 저하 등을 빠르게 파악 |
| 자동 대응(Reaction) | 특정 임계치 초과 시 알림, Auto Scaling 등 자동 처리 |
| 비용 및 성능 최적화 | 불필요한 리소스 사용을 줄이고 효율적인 운영 유도 |
3️⃣ Metric → Monitoring → Response 흐름
| 단계 | 설명 | 예시 |
|---|---|---|
| 1. Metric 측정 | CPU, Memory, Network, Request 등 수집 | CPU 사용률 85% |
| 2. Monitoring | 수집된 데이터를 시계열로 분석 | 5분 평균 CPU 90% |
| 3. Reaction | 임계치 초과 시 자동 대응 | 서버 자동 증설 (Auto Scaling) |
4️⃣ Monitoring의 종류
| 구분 | 설명 | 예시 |
|---|---|---|
| Infra Monitoring | 서버·네트워크 자원 상태 | CPU, Memory, Disk, Network |
| App Monitoring (APM) | 애플리케이션 레벨 성능 | 요청 수, 오류율, 응답 지연 |
| Business Monitoring | 서비스 지표 관점 | 가입률, 결제 성공률, 주문 수 등 |
→ 세 가지를 함께 봐야 진짜 “시스템 건강 상태(Health)”를 파악할 수 있습니다.
5️⃣ Monitoring의 특징
- 자동화 가능 — 조건 기반 알람, Auto Scaling 등
- 저비용 고효율 — Metric은 단순한 수치 데이터이므로 저장·처리 비용이 저렴
- 데이터 기반 진단 — 문제 발생 시 로그나 트레이스보다 빠르게 감지 가능
- 지표 기반 관리 — RED(Request, Error, Duration), USE(Utilization, Saturation, Error) 같은 표준 프레임워크로 설계
6️⃣ 실무 예시
| 항목 | 내용 |
|---|---|
| 상황 (Scenario) | 서버의 5분 평균 CPU 사용률이 60%를 초과하면 자동으로 서버를 하나 더 띄운다. |
| Metric (측정 지표) | CPU Utilization (CPU 사용률) |
| Threshold (임계치) | 5분 평균 60% 초과 시 |
| Action (자동 대응) | Auto Scaling – 신규 인스턴스 자동 생성 |
| Tool (도구 구성) | Prometheus (Metric 수집) Grafana (시각화 및 대시보드) Alertmanager (임계치 감지 및 알림/자동 스케일링 트리거) |
4. 주요 차이
- Monitoring: “지금 문제 있나?”를 메트릭(수치) 으로 빠르게 탐지
- Logging: “무슨 일이, 언제, 왜?”를 이벤트 로그 기록 으로 재구성
- Tracing: “요청이 어디를 거쳐, 어디서 막혔나?”를 요청 흐름 으로 추적
👉 세 가지는 상호보완 관계이며 함께 써야 관찰 가능성(Observability)이 완성됩니다.
| 항목 | 무엇인가 | 데이터 단위/형태 | 잘하는 일 | 한계 | 예시 |
|---|---|---|---|---|---|
| Monitoring | 계측된 메트릭을 수집/집계/시각화 | 시계열 수치(요청 수, 지연, 에러율, 자원 사용량 등) | 이상 탐지·알림, 성능 추세 파악, SLO 모니터링 | 맥락이 적음(“왜”는 약함) | 에러율↑·응답 시간↑를 즉시 감지/알림. (메트릭 질의가 빠르고 비용 효율적) |
| Logging | 시스템/앱 이벤트의 상세 기록 | 텍스트(대개 구조화 JSON) | 원인 파악, 감사/보안 추적, 상세 타임라인 | 데이터 폭증·비용, 검색·보존 전략 필요 | 특정 에러의 스택트레이스, 입력 파라미터, 사용자/엔드포인트 등의 정황 |
| Tracing | 요청의 종단간 경로와 단계별 지연 추적 | Trace(요청) + Span(구간) | 병목 구간 특정, 마이크로서비스 호출 경로 가시화 | 구현/샘플링/저장 비용, 설계 복잡도 | 주문 요청이 Gateway→User→Order→Payment 중 Payment 단계 600ms |
- Enterprise 팁: 메트릭으로 감지 → 로그로 맥락 확인 → 트레이스로 경로/병목 위치 특정
5. 실무 설계 포인트 + Tool
| 영역 | 먼저 결정할 것(설계 포인트) | Tool/Pattern |
|---|---|---|
| Monitoring (메트릭) | 지표 선택: RED(요청·에러·지연), USE(자원 활용) 등 최소 핵심 지표부터 시작 → 서비스별 SLI/SLO 정의 라벨 관리: 고카디널리티 라벨(예: userId, email) 금지. 서비스/버전/리전 등 저카디널리티만 유지 알림 정책: 경보 임계·지속 시간·소유자·런북 연결(과민 경보 방지) |
Prometheus(수집/저장) + Grafana(대시보드/알람) Exemplars로 메트릭→트레이스 점프 연결 오토스케일/자원 최적화와 연계 |
| Logging (로그) | 구조화: JSON 스키마(타임스탬프, 레벨, 서비스명, 트레이스ID 등) 표준화 최소 수집: 불필요 로그 차단(디버그는 환경/샘플 기반), 샘플링/드랍 룰 적용 거버넌스: 보존주기(핫/웜/콜드), PII 마스킹, 접근권한/감사, 색인 전략 |
Loki 또는 Elasticsearch(수집/저장/검색) + Grafana/Kibana(시각화) 수집기는 Promtail/Fluent Bit/OTel Collector 메트릭과 필드 키(key) 동기화로 교차 탐색 용이 |
| Tracing (트레이싱) | 샘플링 전략: 헤드(사전 확률) + 테일(오류/슬로우 보존) 혼합으로 비용·가시성 균형 컨텍스트 전파: W3C traceparent 표준, 게이트웨이/프록시/잡에도 전파 유지범위: “서비스 간(hop)”만 vs “서비스 내부(함수/DB)”까지 — 필요 범위 명확화 |
OpenTelemetry SDK/Agent(계측) + OTel Collector(집중 수집/샘플링/라우팅) 백엔드: Jaeger 또는 Grafana Tempo / (대안 Zipkin) 뷰: Jaeger UI 혹은 Grafana Trace UI |
| 서비스 맵 | 데이터 소스: Envoy 사이드카 메트릭(Prometheus) 기반으로 서비스 간 RPS/지연/에러율 확인 드릴다운: 노드/엣지 → Grafana(메트릭) / Jaeger(트레이스) 링크 |
Kiali(+ Prometheus)로 실시간 서비스 토폴로지 시각화 |
| 표준/운영 | 스키마 표준화: service.name, deployment.environment, http.route, trace_id 등 공통 키 채택운영 자동화: 알람→런북→자동 조치(리트라이/스케일/격리) 파이프라인 비용 관리: 로그/트레이스 보존·샘플·티어링, 메트릭 라벨 제한 |
전 구간 OpenTelemetry 표준화, Grafana로 관제 허브 일원화, SSO/RBAC 적용 |
Service Mesh에서 Observability가 중요한 이유
1. Observability가 중요한 이유
1️⃣ Service Mesh 환경에서 Observability가 중요한 이유
| 이유 | 설명 |
|---|---|
| 1. 마이크로서비스의 복잡성 증가 | 하나의 요청이 수십~수백 개의 서비스(마이크로서비스)를 거침 → 전통적인 모니터링으로는 “요청의 전체 흐름”을 보기 어려움 |
| 2. 분산 환경의 불투명성 | 각 서비스가 독립 배포·확장되기 때문에 장애 지점 식별이 어렵고, 로그/메트릭만으로 원인을 추적하기 힘듦 |
| 3. 사이드카 프록시 구조 | Istio·Envoy는 모든 트래픽을 사이드카가 관찰하기 때문에, 코드 수정 없이 트래픽·지연·에러·의존 관계를 자동 수집 가능 |
| 4. 운영 비용 절감 | 중앙 집중형 Observability 체계를 갖추면 장애 분석 속도 향상, 불필요한 스토리지 비용 절감 |
| 5. 성능 최적화 및 사용자 경험 개선 | 병목 구간, 실패 서비스, 비효율적 호출 경로를 한눈에 파악 → 성능 개선 및 신뢰성 향상 |
2️⃣ Istio에서의 Observability 구성요소
Istio는 모든 서비스 간 통신을 자동 계측하여Metrics,Logs,Traces3가지를 기본 제공
구분 설명 예시 / 도구 Metrics (지표) 트래픽, 지연(latency), 오류율, 포화도(saturation) 등 서비스 상태를 수치화 Prometheus, Grafana Logs (로그) 각 요청의 상세 기록 (source/destination, 응답코드, 지연시간 등) Fluent Bit, Elasticsearch, Kibana Traces (트레이스) 하나의 요청이 여러 서비스를 거칠 때 전체 호출 흐름(Trace)과 단계별 지연(Span) 시각화 Jaeger, Zipkin, Tempo
3️⃣ Metrics의 세 가지 계층
| 계층 | 설명 | 주요 지표 예시 |
|---|---|---|
| Proxy-Level Metrics | Envoy 사이드카가 생성하는 네트워크·트래픽 통계 | 요청 수, 응답 코드 비율, 연결 상태 |
| Service-Level Metrics | 서비스 간 호출의 지연, 트래픽, 오류율, 포화도(RED metrics) | istio_requests_total, istio_request_duration_seconds |
| Control Plane Metrics | Istio 자체 구성요소(Pilot, Mixer 등)의 상태 | 제어 플레인 가용성, 구성 배포 지연 등 |
4️⃣ Logs & Traces
| 구분 | 역할 | 특징 |
|---|---|---|
| Access Logs | 개별 요청 단위의 상세 기록 | 포맷·출력 위치를 자유롭게 설정 가능 |
| Distributed Traces | 요청 흐름 전체 추적, 서비스 간 의존성 분석 | Envoy가 자동 생성한 trace span을 Jaeger/Zipkin으로 전송 |
| Trace Sampling | 트레이스 데이터 양 조절로 성능 부담 완화 | 예: 10% 요청만 트레이싱 |
5️⃣ Observability가 제공하는 가치
| 가치 | 설명 |
|---|---|
| 투명한 서비스 가시성 확보 | 복잡한 분산 구조 속 서비스 간 호출 관계를 실시간으로 시각화 |
| 장애 조기 탐지 및 근본 원인 분석 (Root Cause Analysis) | 오류 발생 시 트레이스를 통해 지연·실패 구간 즉시 확인 |
| 운영 효율성 향상 | 엔지니어가 “무슨 일이 일어났는지”를 바로 파악 → 문제 해결 시간 단축 |
| 데이터 기반 의사결정 | 어떤 서비스가 가장 많이 사용되는지, 리소스가 부족한 구간이 어딘지 식별 |
| 문화적 효과 (DevOps Mindset) | 팀 간 데이터 공유를 통해 “관찰 가능한 시스템” 중심의 개발 문화 형성 |
6️⃣ 실무 예시 요약
| 항목 | 도구 | 역할 |
|---|---|---|
| Metrics | Prometheus + Grafana | 트래픽, 지연, 에러율, 포화도 시각화 |
| Logging | Fluent Bit + Elasticsearch + Kibana | 서비스 요청/응답 상세 로그 수집 |
| Tracing | Jaeger / Zipkin / Tempo | 요청 단위 흐름 추적 및 병목 구간 파악 |
| Service Map | Kiali | 서비스 호출 관계, 지연, 에러율 시각화 |
Netflix의 Observability
| 전략 / 주제 | 설명 / 사례 |
|---|---|
| 다중 신호 활용 (Metrics + Logs + Traces) | 초기에는 메트릭 중심이었지만, 단순 메트릭만으로는 원인 파악이 한계. 그래서 로그와 분산 트레이스를 함께 분석하는 방식으로 전환 |
| 내부 툴 “Mantis” 사용 | 로그 스트림을 필터링하고 실시간 쿼리를 처리하기 위한 내부 시스템. 로그를 노드에서 먼저 필터링한 뒤, 필요한 것만 중앙 Mantis 클러스터로 전송 |
| 지표 시스템 “Atlas” | Netflix 내부의 시계열 지표 시스템. 메트릭 수집, 다차원 분석, 대시보드 등에 사용 |
| 데이터 보존 vs 비용 절감 타협 | 모든 로그를 무한 저장할 수는 없으므로 보존 기간을 조정함 (예: 2주 → 1주 등) |
| Trace 데이터 저장 구조 전환 | 초기엔 Elasticsearch에 저장했지만, 인덱싱 지연 및 확장성 문제로 Cassandra로 이전하여 처리율과 성능 개선 |
| Trace 이벤트 처리 파이프라인 | 앱 노드 → Kafka → Mantis job에서 trace 이벤트를 조합(stitch) → 영속 스토리지에 저장하는 파이프라인 구성 |
| 자동 계측 및 플랫폼 엔지니어링 지원 | 모든 서비스 이미지/AMI에 Mantis agent, Atlas 클라이언트 등이 기본 장착되어 배포됨 → 개발자가 직접 삽입하지 않아도 Telemetry가 어느 정도 확보 |
| 상관 분석 & 인텔리전스 추가 | 단순한 trace 시각화 외에도, 로그 + 메트릭 + trace 데이터를 통합해 “왜 4K 영상이 제공되지 않았는가” 같은 인사이트를 사용자 수준으로 연결하려는 시도 |
질문
1. 서비스 코드 안에 OpenTelemetry 등의 라이브러리를 넣어서 Trace를 수집하는 것은 서비스 메시의 장점, 철학을 포기하는 것 아닌가?
1️⃣ 철학
- 서비스 메시: 애플리케이션 코드에 손대지 않고, 네트워크 단에서 모든 인프라적 요소를 제어
2️⃣ Istio가 못 보는 영역
- Istio(Envoy)는 네트워크 프록시이기 때문에, 서비스 내부에서 무슨 일이 일어나는지는 모름
OrderService { controller -> service -> repository -> DB query } - Envoy는 여기에서 요청이 들어오고 나간 시간만 알 수 있음 - 내부에서 DB 쿼리가 200ms, 외부 API가 300ms 걸렸는지는 알 수 없음
→ Istio만으로는 “왜 느린지”, “어디가 병목인지” 까지는 추적 불가능
3️⃣ 서비스 내부 라이브러리(e.g. OpenTelemetry)의 역할
| 구분 | Istio (Service Mesh) | OpenTelemetry |
|---|---|---|
| 관찰 범위 | 서비스 간 통신 | 서비스 내부 로직 |
| 작동 위치 | 네트워크 레이어 (L7 Proxy) | 애플리케이션 코드 (SDK/Agent) |
| Trace 단위 | A → B → C (서비스 경로) | Controller → Service → DB (내부 단계) |
| 코드 수정 | 불필요 | SDK 설정 필요 |
| 주 목적 | 외부 트래픽 제어 & 가시화 | 내부 처리 과정 분석 & 세부 Trace 수집 |
→ OpenTelemetry를 서비스에 넣는다고 해서 Service Mesh의 목표를 포기하는 것이 아닌, Mesh가 해줄 수 없는 영역(비즈니스 로직
내부) 까지 보완하는 것
4️⃣ 실무 구성
[서비스 내부]
└── OpenTelemetry SDK ← 내부 로직 Trace
│
▼
[Envoy Sidecar] ← 서비스 간 Trace, Metrics
│
▼
[OpenTelemetry Collector] ← 통합 수집
├──→ Jaeger (Trace)
├──→ Prometheus (Metrics)
└──→ Loki (Logs)
→ Jaeger에서 한 요청의 “서비스 간 hop + 내부 함수 로직” 을 한 번에 볼 수 있음
2. Envoy가 수집하는 Trace vs OpenTelemetry가 수집하는 Trace 확실한 차이 + Jaeger 대시보드는 어떻게 구성?
3. Tracing에서의 다단계 호출, 비동기 시스템 추적 방법
출처
1. Logging, Tracing, Metric 의 개념 및 차이점
2. Tracing vs Logging vs Monitoring: What’s the Difference?
3. Logging vs Metrics vs Tracing: What's the Difference?
4. Logging, Tracing, and Metrics
5. Three Pillars of Observability: Logs vs. Metrics vs. Traces
6. Istio 공식 문서 - Observability
7. Why is Distributed Tracing in Microservices needed?
8. Observability in Service Mesh
9. Netflix-Observability
'Istio 공부' 카테고리의 다른 글
| Istio mTLS 내부 동작 원리 - istiod가 인증서(Cert) 발급·배포·갱신하는 방법 (0) | 2025.10.12 |
|---|---|
| Istio에서의 Observability (0) | 2025.09.28 |
| 서비스 메시(Service Mesh)란 무엇일까? (0) | 2025.09.15 |