🔎 Observability란 무엇인가?
Observability(관찰 가능성)는 시스템의 외부에서 수집되는 신호(메트릭, 로그, 트레이스 등)를 통해 내부 상태를 이해하고 추론할 수 있는 능력을 의미합니다.
즉, 내부에서 무슨 일이 일어나는지 직접 볼 수 없어도, 외부 지표만으로 시스템이 안정적으로 동작하는지, 문제가 언제/왜 발생했는지 파악할 수 있는 특성입니다.
Observability의 핵심 목표는 단순히 알림을 주는 것을 넘어, 예측할 수 없는 장애 상황을 빠르게 인지하고 문제 해결로 이어지는 인사이트를 제공하는 것입니다.
마이크로서비스 아키텍처(MSA) 환경에서는 장애 원인을 특정하기 어렵고, 서비스 간 호출 체인 전체에서 지연, 실패, 에러율 같은 지표를 추적해야 되기 때문에 Observability 도구와 계측 기법은 장애 발생 시 빠른 복구를 위한 필수 요소입니다.
🖥️ Monitoring과의 차이
| 구분 | Monitoring (모니터링) | Observability (관찰 가능성) |
|---|---|---|
| 정의 | 사전에 정의된 지표와 상태를 추적하고 알림 제공 | 외부 신호(메트릭, 로그, 트레이스)로 내부 상태를 추론하고 이해 |
| 관점 | “문제가 생겼는가?”에 집중 | “왜, 어디서 문제가 생겼는가?”에 집중 |
| 기능 | 임계값 초과 시 경고 발생 (CPU, 메모리, 에러율 등) | 시스템 동작의 맥락을 이해하고 원인 분석 가능 |
| 범위 | 제한적 (사전 정의된 메트릭 중심) | 포괄적 (모니터링 포함 + 새로운 문제도 파악 가능) |
| 목표 | 문제를 빠르게 감지하고 알림 제공 | 예측 불가능한 문제까지 빠르게 파악하고 해결 지원 |
| 한 줄 요약 | 알림(Notification) | 이해와 문제 해결(Insight & Troubleshooting) |
🚦 Istio에서의 Observability
Istio는 서비스 메시(Service Mesh)로, Envoy 프록시를 각 서비스에 사이드카(sidecar)로 주입합니다. 이 덕분에 애플리케이션 코드를 수정하지 않고도 트래픽을 가로채 다양한 데이터를 수집할 수 있습니다.
📌 Istio Observability의 특징
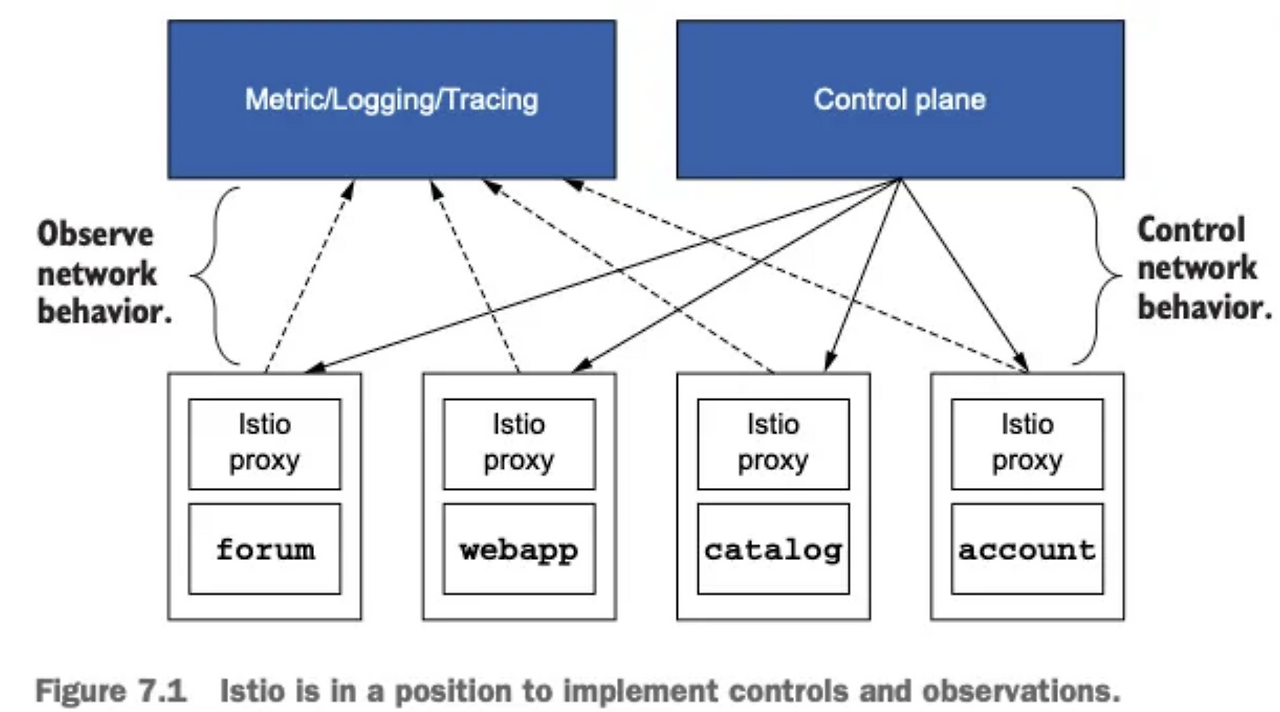
1. 데이터 플레인(Data Plane) — Istio Proxy 기반 수집
- 각 서비스 앞에 Istio Proxy(Envoy)가 붙어 있어 요청 수, 지연 시간, 오류율 같은 상세 메트릭을 가장 적절하게 수집
- 프로세스 외부(Out-of-Process) 에서 동작하므로, 애플리케이션에 별도 라이브러리 추가 불필요
2. 관측(Observability) — Metric/Logging/Tracing
Istio Proxy를 통해 수집한 Telemetry 데이터는 Prometheus, Grafana, Jaeger 같은 외부 시스템으로 전달되어 시각화 및 모니터링에 활용됩니다.
-> 이를 자동화된 Telemetry라고 합니다.
3. 제어(Control) — Control Plane
Control network behavior: Control Plane은 각 Istio Proxy가 어떻게 동작할지 정책(Policy)과 규칙(Rule) 을 내려줍니다.
예시
- “catalog 서비스로 가는 트래픽은 10%만 v2 버전으로 보내라” (Canary 배포)
- “webapp 서비스는 초당 100건 이상 요청이 오면 차단해라” (Rate Limiting)
4. 표준 Istio 메트릭
Istio를 설치하면 기본 활성화되는 메트릭으로, 대부분의 운영 환경에서 가장 많이 활용됩니다.
Envoy 프록시의 관리 포트(localhost:15000/stats)에서 확인할 수 있으며, Prometheus를 통해 자동 수집됩니다.
| 메트릭명 | 설명 |
|---|---|
| istio_requests_total | 총 HTTP/gRPC 요청 수 (카운터) |
| istio_request_duration_milliseconds | 요청 처리 시간 분포 (히스토그램) |
| istio_request_bytes | 요청 크기 (바이트) |
| istio_response_bytes | 응답 크기 (바이트) |
| istio_tcp_sent_bytes_total | 전송한 TCP 바이트 수 |
| istio_tcp_received_bytes_total | 수신한 TCP 바이트 수 |
| istio_grpc_* | gRPC 요청/응답 관련 메트릭 |
👉 특징: HTTP, HTTPS, TCP, gRPC 등 주요 프로토콜을 모두 지원합니다.
👉 장점: 기본 메트릭만으로도 요청량, 지연 시간, 에러율 같은 핵심 서비스 지표를 충분히 모니터링할 수 있습니다.
5. 확장성
표준 메트릭 외에도 Envoy는 더 세밀한 운영 지표를 제공합니다. 하지만 기본적으로는 비활성화되어 있으며, 필요할 때만 선택적으로 활성화해야 합니다. 활성화 방법은 다음과 같습니다.
- Istio Operator 명세 수정 (메시 전체 적용)
- 워크로드 애노테이션 (특정 워크로드만 적용)
- Telemetry API (가장 유연하고 권장되는 방식)
‼️ 주의: 확장 메트릭은 데이터량이 많아 성능 부담을 줄 수 있으므로, 꼭 필요한 메트릭만 선별적으로 켜는 것이 바람직합니다.
🔎 Telemetry
Telemetry는 수많은 마이크로서비스에서 발생하는 데이터를 자동으로 수집하고 추적(Tracing)하는 프로세스를 의미합니다.
👉 쉽게 말해, 서비스 간에 어떤 요청이 오가고, 얼마나 걸리고, 어디서 문제가 발생하는지 기록하고 관찰하는 기능입니다.
⚙️ Istio에서 Telemetry의 역할
Istio는 서비스 메시(Service Mesh)로서 8가지 주요 기능을 제공하는데, 그중 Telemetry는 특히 중요한 기능입니다.
👉 Istio Telemetry는 Envoy Proxy를 통해 서비스 간 모든 트래픽을 추적하고, Kiali/Jaeger로 시각화하여 마이크로서비스 간의 네트워크 상호작용을 추적할 수 있고, 운영자가 이를 바탕으로 서비스 전체 상태를 관찰(Observability)할 수 있게 해줍니다.
1️⃣ Telemetry v1
Istio 1.8 이전 버전에서는 Mixer라는 컴포넌트를 통해 서비스 메시의 메트릭과 정책을 관리했습니다.
Mixer는 각 Envoy Proxy와 연결을 맺고, 서비스 간 트래픽에서 발생하는 메트릭을 수집해 Prometheus 같은 모니터링 시스템으로 전달하는 역할을 담당했습니다.
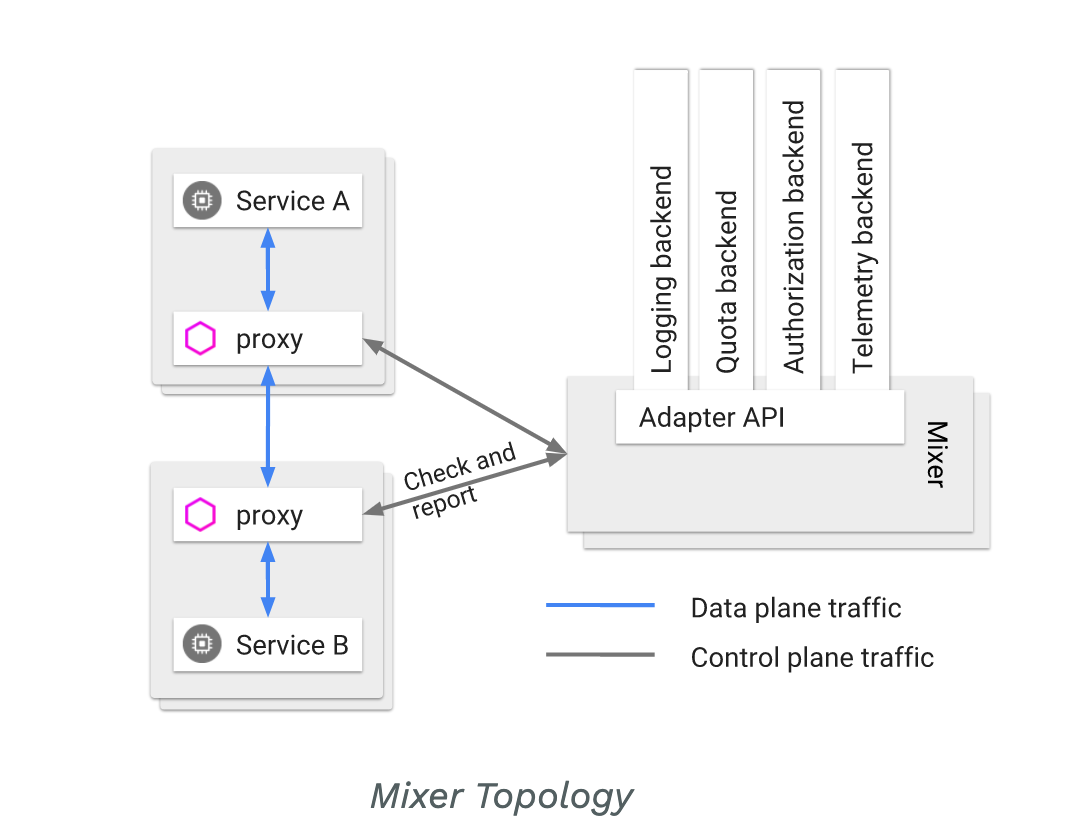
⚙️ Mixer 동작 방식
Mixer는 Configuration Model이라는 구조를 통해 Envoy에서 받은 Attribute(속성 데이터)를 처리했습니다.
Configuration Model은 크게 세 가지 요소로 구성됩니다.
1. Instance
Envoy Proxy에서 수신한 Attribute를 어떤 템플릿 형태로 변환할지 정의
예: 요청 소스, 목적지, 값 등을 담아 메트릭 데이터 구조 생성
2. Handler
Instance 데이터를 어떤 Adapter(백엔드)로 보낼지 정의
예: Prometheus Adapter에 맞게 JSON Payload나 메트릭 형식으로 변환
3. Rule
특정 조건(TCP 트래픽 등)에 맞을 때 Instance와 Handler를 매핑
-> 이를 통해 원하는 상황에서만 메트릭을 전송할 수 있음
⚠️ 한계와 Deprecated
Mixer는 Envoy Proxy마다 연결을 맺어야 했기 때문에 리소스 사용량이 많고 성능 부담이 크고, 구조가 복잡하여 운영 효율이 떨어졌습니다.
👉 결국 Istio 1.8부터는 Mixer가 제거되고, Telemetry v2(Envoy Proxy가 직접 메트릭을 노출하는 구조)로 전환되었습니다.
🔎 Telemetry v2란?
Istio 1.8 이후부터 Telemetry는 Mixer 기반 구조(v1)에서 WASM(WebAssembly) 기반 구조(v2)로 완전히 바뀌었습니다.
기존 Mixer 방식의 한계를 해결하기 위해 Istio는 Telemetry를 Envoy Proxy 내부에서 직접 처리하도록 아키텍처를 재설계했습니다.
👉 결과적으로 Telemetry v2는 더 적은 CPU와 메모리 사용량, 더 낮은 지연시간을 보장합니다. (공식 문서에 따르면 지연시간을 50~90%, CPU 사용량을 약 50% 줄였습니다.)
| 구분 | Telemetry v1 (Mixer 기반) | Telemetry v2 (WASM 기반) |
|---|---|---|
| 구조 | Envoy → Mixer → Prometheus | Envoy Proxy → Prometheus |
| 처리 방식 | Mixer가 중앙에서 메트릭을 가공 후 백엔드로 전달 | Envoy가 직접 메트릭 생성 및 노출 |
| 장점 | 유연한 Adapter 구조 | 경량화, 낮은 지연시간, CPU 사용량 절감 |
| 단점 | 중앙 집중식 → 성능 저하, 리소스 과다 사용 | 일부 기능은 WASM 플러그인 구현 필요 |
| 확장성 | Adapter 방식 (제한적, 복잡) | WASM 기반 플러그인으로 손쉬운 확장 가능 |
📊 Telemetry v2의 핵심 구성
Telemetry v2는 Envoy Proxy에 내장된 두 가지 플러그인을 통해 서비스 레벨 메트릭을 수집합니다.
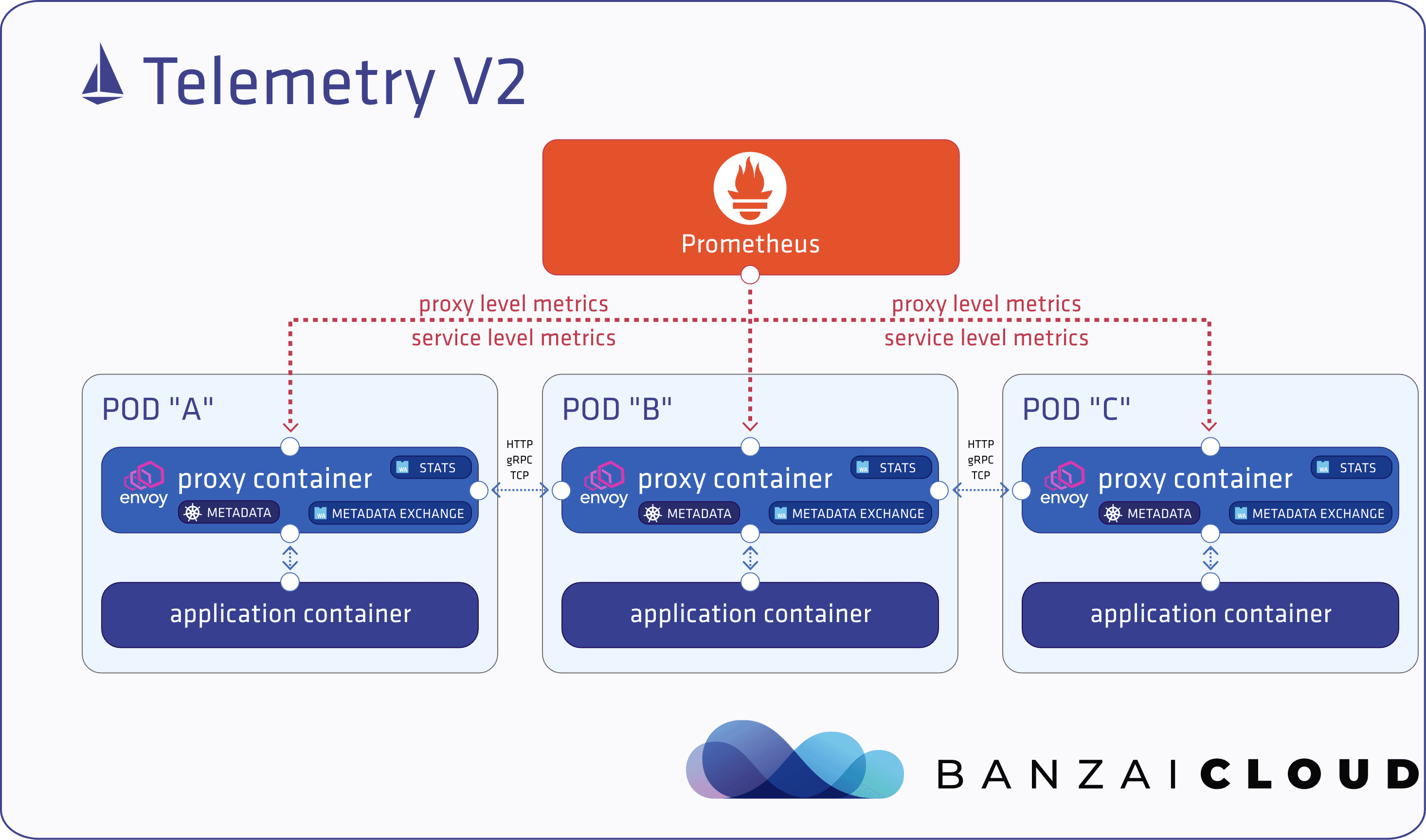
1. Metadata Exchange Plugin
- 서비스 레벨 메트릭을 위해 클라이언트/서버 정보를 교환
- Envoy Proxy는 기본적으로 자기 자신 외의 Proxy 정보를 모르기 때문에, 이를 해결하기 위해 HTTP 헤더 필드(envoy.wasm.metadata_exchange.*)나 ALPN 기반 터널링을 활용 (HTTP의 경우 헤더 필드, TCP의 경우 ALPN 기반 터널링을 통해 전달)
- 단, Istio 메시 내부 통신에는 유효하지만 외부 클라이언트와의 통신에서는 한계가 있음
👉 단일 Envoy Proxy가 아닌 서비스 레벨 관점에서 메트릭을 만들 수 있음.
2. Stats Plugin
- Envoy Proxy의 inbound/outbound 트래픽을 기록
- Prometheus가 수집할 수 있는 형식으로 메트릭 노출
- 기본 제공 메트릭: 요청 수, 응답 지연 시간, 응답 코드, TCP 바이트 송수신량 등
3. Metadata 모듈
- 서비스 이름, 워크로드 이름 등 Pod 및 서비스 메타데이터를 관리
- 단순한 숫자 메트릭이 아니라 “이 요청은 A 서비스에서 B 서비스로 갔다” 같은 의미 있는 데이터를 제공
4. 결론
-> Telemetry v2는 단순히 성능을 개선한 수준을 넘어, 서비스 메시에서의 관측성(Observability)을 더 가볍고 확장 가능하게 만든 혁신적인 변화
🚀 WebAssembly(WASM)의 역할
WebAssembly는 원래 웹 브라우저에서 고성능 애플리케이션 실행을 위해 설계된 기술이지만, Istio는 이를 Envoy Proxy 확장에 도입했습니다.
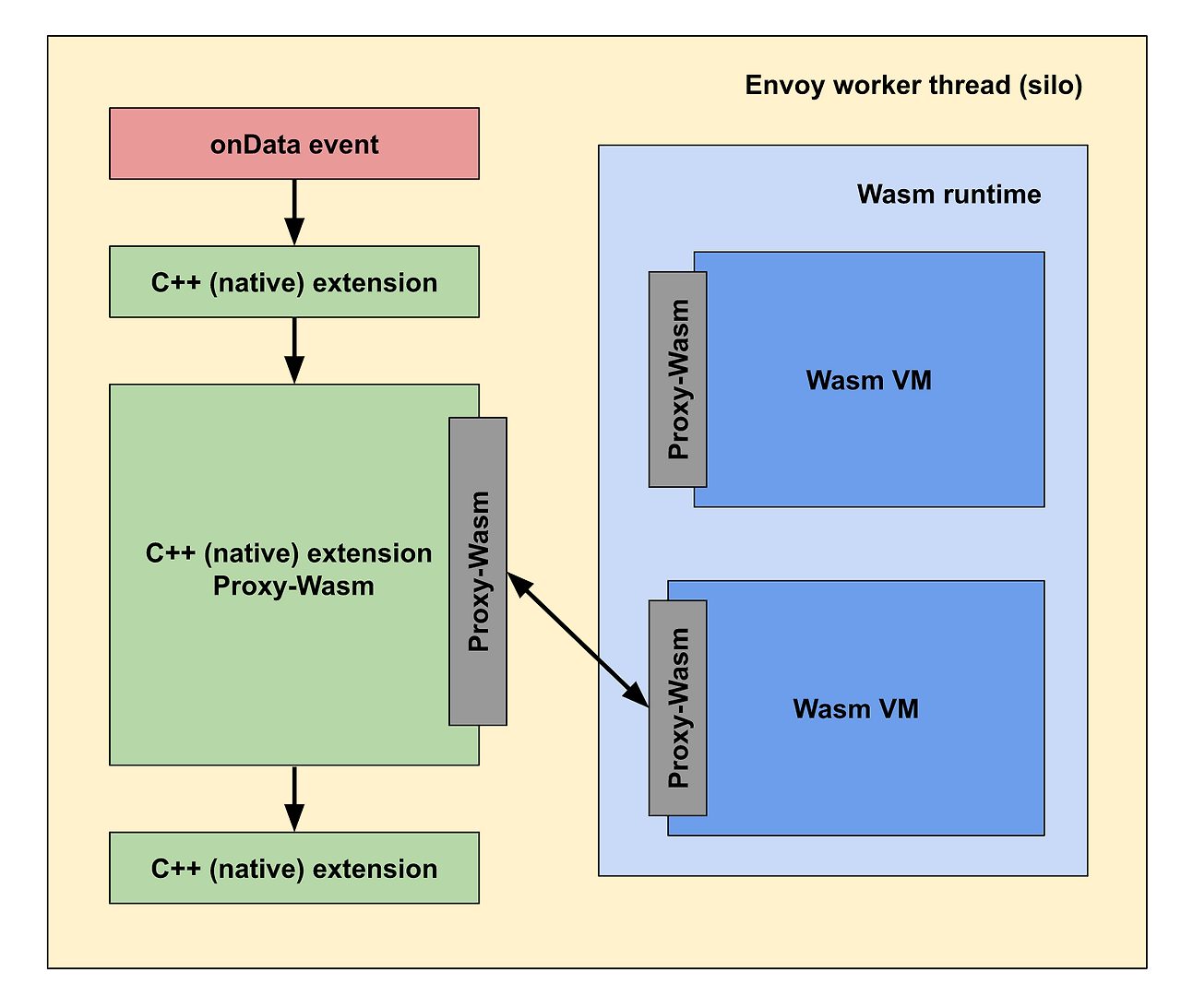
1. 이전 방식의 문제
Envoy 확장을 위해서는 C++로 코드를 작성하고 Envoy를 다시 빌드해야 했음
→ 러닝커브가 높고 배포가 번거로움.
2. WASM 도입 후
- 개발자가 원하는 기능을 Go, Rust 등 다양한 언어로 작성 → WASM 플러그인으로 컴파일
- Envoy Proxy가 이를 런타임에 로드해서 실행
- 재빌드 불필요, 핫플러그 가능 → 훨씬 유연한 확장성 확보
👉 WASM은 경량 VM 기반 확장성을 제공해, 필요에 따라 Custom Metric, 보안 로직, 데이터 가공 기능 등을 쉽게 추가할 수 있습니다.
📊 Grafana가 Prometheus 지표를 활용해 시각화하는 방식
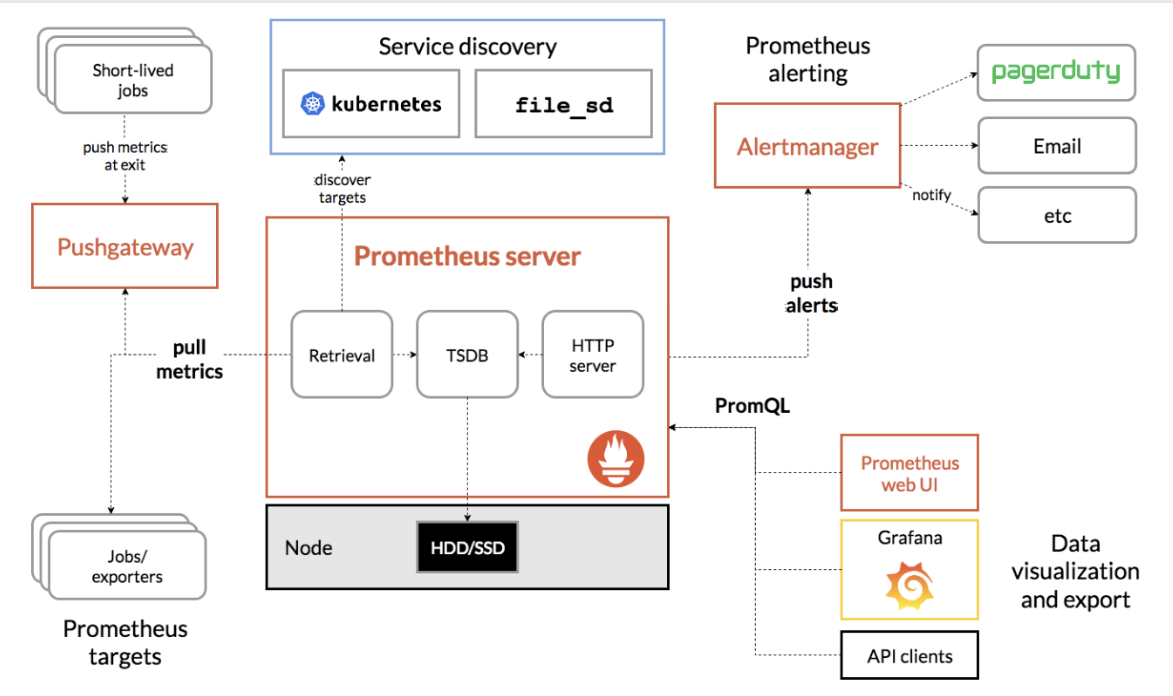
1️⃣ Prometheus가 지표 수집
1. Envoy Proxy (Istio 사이드카)
각 Pod에 주입된 Envoy Proxy는 /stats/prometheus 같은 HTTP 엔드포인트를 통해 메트릭을 노출 (표준 Istio 메트릭이 포함)
2. Prometheus (Pull 방식)
- Prometheus는 Exporter(Node Exporter, SQL Exporter 등)를 통해 서버·애플리케이션 메트릭을 Pull 방식으로 수집
👉 Envoy Proxy의 메트릭 엔드포인트를 주기적으로 Pull(HTTP GET 요청)
3. TSDB 저장
- 수집된 데이터는 시계열 데이터(TSDB, Time Series Database) 형태로 로컬 디스크에 저장
- 메트릭은 metric_name{label=value} 형태로 저장되어, 다양한 라벨 기준(서비스명, 인스턴스, 상태 코드 등)으로 필터링 가능
2️⃣ PromQL로 데이터 질의
- Prometheus에 저장된 메트릭은 PromQL(Prometheus Query Language)로 질의할 수 있음.
- 예시rate(http_requests_total[5m]) → 5분 동안의 HTTP 요청 증가율avg(node_cpu_seconds_total{mode="idle"}) → CPU idle 평균 비율
3️⃣ Grafana에서 Prometheus 연동
- Grafana는 Prometheus를 데이터 소스(Data Source)로 등록
- Grafana의 대시보드에서 PromQL 쿼리를 실행해 메트릭을 가져옴
4️⃣ 시각화
가져온 메트릭은 Grafana에서 다양한 형태로 시각화 가능
- 그래프: 시간에 따른 변화 (CPU 사용률, 요청 수 등)
- 게이지/바 차트: 특정 지표의 현재 상태
- 테이블: 라벨별 세부 값 표시
- 히트맵/분포도: 지연 시간, 에러율 같은 분포 데이터
5️⃣ 알림(Alerting)
- Grafana는 Prometheus의 Alertmanager와 별도로 자체적인 알림 규칙(Alert Rule)을 설정 가능
- 특정 지표가 임계값을 넘으면 이메일, Slack, Teams 같은 채널로 알림을 발송할 수 있음
출처
3. 메트릭과 트레이싱으로 살펴보는 Istio Observability
4. Service Monitoring in Istio
'Istio 공부' 카테고리의 다른 글
| Istio mTLS 내부 동작 원리 - istiod가 인증서(Cert) 발급·배포·갱신하는 방법 (0) | 2025.10.12 |
|---|---|
| Observability의 개념과 필요성 (0) | 2025.10.05 |
| 서비스 메시(Service Mesh)란 무엇일까? (0) | 2025.09.15 |